일변량 자료 요약
(1) 수치형 - 평균,중앙값,최빈값, 분산, 표준편차, 범위, 분위수 등
(2) 범주형 - 도수분포표 (빈도수, 백분율)
다변량 자료 요약
(1) 수치형 - 공분산, 상관관계
(2) 범주형 - 분할표 (빈도수, 백분율)
(1) 일변량 자료에 대한 수치적 기술통계

위 자료는 신체검사 결과를 나타내고 있는 자료이다.
위 자료에서 일변량 자료란 성, 연령, 신장, 체중 등 각 변수 한 항목을 말한다.
예를 들어 신장에 대한 평균을 구할 수 있지만, 신장과 체중을 합친 두 변수의 평균을 구하는 것은 오히려 혼선을 준다.
다변량 자료에 대한 요약은 공분산과 상관계수 등을 구할 수 있다.
위 자료에서 성, 비만도, 혈액형은 범주자료이고 자료요약은 도수분포표로 할 수 있다.
따라서 일변량 자료에 대한 수치적 기술 통계라는 것은 일변량 즉 하나의 변수 자료중 수치자료에만 적용할 수 있다.
즉 평균,분산 등의 일변량 수치자료에만 사용할 수 있는 통계량(요약값)이다.
위 자료에서 평균을 구할 수 있는 변수는 연령, 신장, 체중, 충치 등이다.
(2) 수치자료 위치의 대표값
연속형 수치자료의 중앙을 나타내는 대표적인 통계량(요약값)은 다음 3가지를 들 수 있다.
- 평균 : 데이터의 총합을 데이터의 개수로 나눈 값
- 중앙값 : 자료를 순서대로 나열했을 때 가운데 값 만약 관측치의 개수가 짝수라면 가운데에 가장 가까운 두 개의 값의 평균을 사용
- 최빈값 : 가장 많이 관측되는 값
평균이나 중앙값, 최빈값이 대표값되는 이유는 이 값들이 자료 분포의 중심 위치에 있기 때문이다. 통상 중심을 기준으로 많은 값들이 분포하고 있는 경우가 많기도 하다.
(3) 평균
평균(mean)은 자료의 총합을 자료의 개수로 나눈 값으로서, 자료의 대푯값을 나타내는 대표적인 방법 중 하나이다. 가장 많이 사용하는 중심위치 통계값은 평균이라 할 수 있다.
평균을 다음과 같이 나눌 수 있다.
- 산술평균(Arithmetic mean): 자료의 총합을 자료의 개수로 나눈 값
- 기하평균(Geometric mean): 자료의 곱을 자료의 개수 제곱근으로 나눈 값
- 조화평균(Harmonic mean): 자료의 개수를 자료의 각 항의 역수의 총합으로 나눈 값
- 가중평균(Weighted mean): 자료의 가중치를 곱한 값의 총합을 가중치의 총합으로 나눈 값
각각의 평균은 자료의 특성에 따라 적합한 평균이 다르게 적용될 수 있다. 예를 들어, 상대적인 크기나 비율의 차이가 중요한 경우에는 기하평균이나 조화평균을 사용하는 것이 적절할 수 있다. 또한, 자료의 가중치가 있는 경우에는 가중평균을 사용한다. 그러나 일반적으로는 가장 많이 사용되는 것은 산술평균이다. 통계학에서는 모집단의 특성을 알기 위한 표본을 추출하는 것에 관심이 많기 때문에 주로 표본평균, 표본분산 등 표본이라는 말을 앞에 붙여 사용한다.
▶ 표본평균 (sample mean)
표본평균은 표본의 합을 표본크기로 나눈 값이다. 산술평균이다.
모집단의 평균은 모평균이라고 부른다.
표본평균의 일반식

☞ 평균은 무게중심이기도 하다.
▶ 표본비율 (sample proportion)
모집단에서 추출한 표본들이 어떤 특징을 가지는 것들의 비율이다.
i 번째 관측값이 어떤 범주에 속하면 Xi 의 값을 1, 아니면 0 이라 표시한다면,

y 는 해당범주에 포함된 표본의 수를 나타낸다. 그리고 표본비율은 아래와 같이 나타낼 수 있다.

즉, 표본비율 = 표본평균 임을 알 수 있다.
▶ 평균의 한계
평균은 데이터의 중심을 대표하는 대표값 중 하나이지만, 모든 경우에서 좋은 대표값이 될 수는 없다. 평균의 한계는 다음과 같다.
- 이상점(outlier)에 민감하다: 이상치는 데이터 집합의 값 중에서 다른 값들과 동떨어져 있는 값으로, 평균을 구할 때 이상치가 포함되면 평균 값이 크게 영향을 받게 된다.
- 분포의 형태에 따라 왜곡될 수 있다: 데이터가 한쪽 방향으로 치우쳐져 있거나, 두 개 이상의 그룹으로 나뉘어져 있을 경우에는 평균이 전체 데이터의 대표값이 아닐 수 있다.
- 비교할 때 주의가 필요하다: 두 집단의 평균을 비교할 때에는 데이터 분포의 형태와 이상치의 영향을 고려해야 합니다. 또한 집단의 크기가 다르면 평균을 비교하는 것이 공정하지 않을 수 있다. 이러한 경우에는 중앙값이나 백분위수를 사용하는 것이 더 적합하다.
따라서 평균을 사용할 때에는 이러한 한계를 인지하고, 데이터의 특성과 목적에 따라 적절한 대표값을 선택해야 한다.
▶ 이상점(outlier)
예를 들어, " 100,110,120,130,140,120,120,800 " 8개 자료의 평균은 205가 나온다. 800 이라는 숫자는 다른 숫자들과 많이 떨어져 있어 평균의 값을 크게 높여준다. 이렇듯 대부분의 관측값으로부터 멀리 떨어져 있는 일부 관측값을 이상점이라고 한다.
⇒ 이상점의 포함여부에 따라 평균의 값이 크게 차이가 날 수 있다. 즉, 자료분석에 있어 왜곡현상을 만들어 낼 수 있다는 의미이다.
⇒ 대체 통계값 : 중앙값, 절사평균, 최빈값 등
※ "로버스트 Robust" 의 사전적의미는 "강건한"이란 뜻이다. 통계학에서는 이상점에 영향을 받는지 받지 않는지에 대한 표현에 쓰인다. 로버스트한 통계량이라 한다면 이상점에 영향을 받지 않는다라는 의미이다. 평균은 로버스트하지 않은 통계량이라고 할 수 있다.
▶ 심슨의 역설 (Simpson’s Paradox)
데이터의 세부 그룹별로 일정한 추세나 경향성이 나타나지만, 전체적으로 보면 그 추세가 사라지거나 반대방향의 경향성이 나타나는 현상을 의미한다.
◈ 사례 : 버클리 대학은 대학원 입시에서 성차별을 하였나?
1970년대 미 버클리대학은 대학원 입시에서 성차별이 있었다는 문제 제기를 받게 된다. 그해 대학원 입시 결과에서 남학생들의 합격률은 45%, 여학생들의 합격률은 30%였다.
대학원 입시는 각 학과에서 관리를 하기 때문에 대표적인 6개 전공에서 남학생과 여학생의 합격률을 비교한 결과는 다음과 같았다.
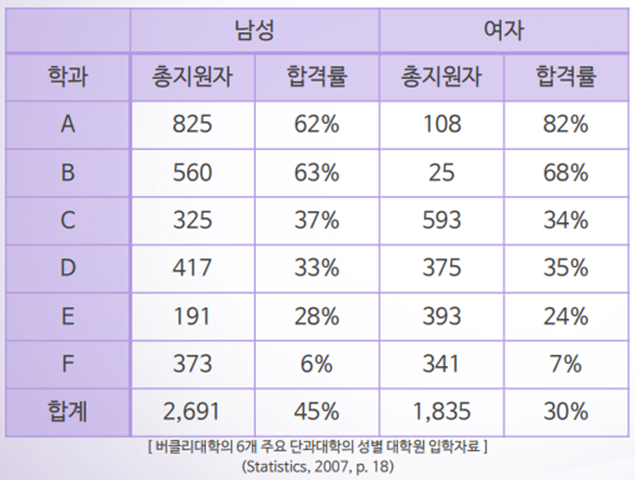
- 전체합격률은 남학생이 높지만, 학과별 합격률은 여학생이 높다!
- 이 이유는 남학생들은 다수가 합격률이 높은 A,B학과에 지원하였지만, 여학생들은 극소수가 이들 학과에 지원하여 여학생 전체 합격률은 주로 C,D,E,F 학과 합격률에 의해 결정되었고 남학생들의 전체합격률은 A,B학과의 높은 합격률에 힘입어 상승하였다.
- 이렇게 제 3의 요인으로 전체자료를 세분화했을 때 정반대의 결과가 나오는 것을 심슨의 역설(Simpson’s paradox)라고 한다.
- 이 예제에서 주목할 점은 학과와 합격률, 그리고 학과와 성별 지원자 숫자 사이에 강한 연관성이 있어서 전체 성별 합격률에 영향을 미쳤다는 점이다.
▶ 교락 효과 (Confounder Effect)
- 교락 요인(confounder)는 앞의 예제에서 같이 반응변수(합격 여부)와 설명변수(성별)에 모두 영향을 미치는 변수(학과)를 말한다.
- 교락 요인을 통제하여야만 반응변수가 순수하게 설명변수에 미치는 영향을 알 수 있다.
- 교락 요인을 통제하기 위해서 ① 교락 요인의 값에 따라 그룹을 나눈 후 반응변수와 설명변수의 관계를 알아본다 (subgroup analysis). ② 가중평균을 사용한다.
▶ 평균의 한계를 보여 주는 동영상 : EBS 지식채널 “48분의 함정” : https://youtu.be/mo9wfhY35I4
▶ 가중평균 (Weighted mean) : 자료의 가중치를 곱한 값의 총합을 가중치의 총합으로 나눈 값
수치자료에 가중치를 더해 구한 평균값이다.
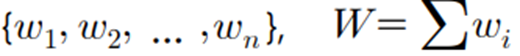
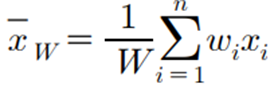
◈ 사례 : 버클리 대학은 대학원 입시에서 성차별을 하였나?
위 사례에서 남성 지원자의 가중치를 반영한 합격률(가중평균)을 구하면,
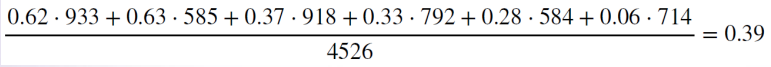
전체 지원자 중 그 학과에 지원하는 사람의 비율을 가중치로 한 후 가중치를 학과별 합격률에 곱하여 남학생의 가중치를 반영한 합격률을 구하면 된다. 앞서 가중치 없이 계산한 남성지원자의 합격률 평균은 45% 였다.
즉 학과별로 지원하는 남녀지원자 숫자가 다르다는 점을 통제하기 위해 성별 지원자 비율이 아닌 전체 비율을 가중치로 사용하는 것이다.
여학생의 경우 같은 방법으로 가중치를 구하면 43%가 나온다.
▶ 기하평균 (geometric mean) : 자료의 곱을 자료의 개수 제곱근으로 나눈 값
곱셈으로 계산하는 값에서의 평균을 계산하고자 할 때 산술평균이 아닌 기하평균을 사용한다.
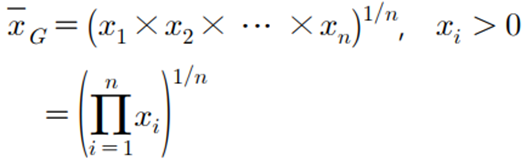
◈ 사례 : 1인당 총소득이 1985년 209.0 만 원이고 2015년 3093.5 만 원이라고 할 때 연평균 증가율은 ?
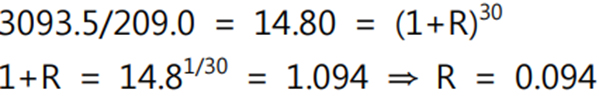
▶ 조화평균 (harmonic mean) : 자료의 개수를 자료의 각 항의 역수의 총합으로 나눈 값
주어진 수들의 역수의 산술평균의 역수를 말한다. 평균적인 변화율을 구할 때에 주로 사용된다.
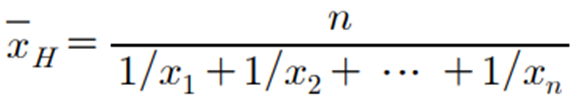
◈ 사례 : 절반의 거리를 시속 60km로 달리고 남은 절반의 거리를 시속 40km로 달릴 때 평균 속도는?

(4) 중앙값
가장 많이 사용하는 중심위치 통계값은 평균이다. 이 평균의 한계로 인하여 사용할 수 있는 대체 중심위치 통계값으로는 중앙값, 최빈값 등이 있다.
▶ 표본중앙값 (sample median, 표본중위수)
절반 이상의 숫자들이 이 값보다 크거나 같고 동시에 절반 이상의 숫자들이 이 값보다 작거나 같은 수이다.
중앙값은 n이 홀수이면 (n+1)/2번째로 크거나 작은 숫자이다
중앙값은 n이 짝수이면 n/2번째 숫자와 (n+1)/2번째 숫자의 평균으로 정의한다.
일반식으로 표현하면,
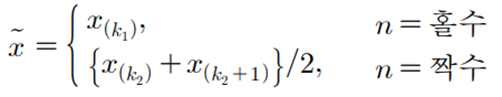
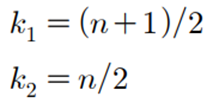
앞서 " 100,110,120,130,140,120,120,800 " 8개 자료의 평균은 205가 나왔다. 이 자료의 중앙값은 120이다.
이상점 800이 1000으로 바뀌어도 중앙값은 바뀌지 않는다. 즉, 표본중앙값은 극단적인 값에 영향을 받지 않는다.
이상점의 유무에 관계없이 안정적인 중심위치를 제공한다. 즉 이상점에 중앙값은 로버스트한다.
그러나, 자료의 값들은 순서통계량을 구하는데 이용될 뿐이고 중앙에 있는 하나 또는 두 개의 관측값만 사용한다. 그런 탓에 자료의 정보를 다 활용하지 못하는 단점이 있기도 하다.
▶ 표본절사평균 ( sample trimmed mean )
표본평균은 모든 자료의 정보를 사용하지만 이상점에 로버스트 하지 않고, 표본중앙값은 로버스트 하지만 자료의 정보를 다 활용하지 못한다. 평균과 중앙점의 장점을 취합해 만든 것이 표본절사평균이다.
- a % 표본절사평균 : 순서통계량에서 하위 a %부터 상위 a%까지의 자료를 이용하여 표본평균을 계산
- a 백분위수(percentile) : 하위 a %에 해당하는 값
- p = a/100이면 p분위수(quantile)
- a를 적절히 정하면 이상점을 제외시키면서 많은 표본정보 이용
- a = 0 이면 표본평균 이고, a = 50 이면 표본중앙값이다.
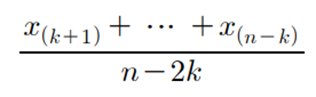
앞서 " 100,110,120,130,140,120,120,800 " 8개 자료에서 최소값과 최대값을 제외한 절사평균은 123.3 이다. ( 평균은 205, 중앙값은 120 )
☞ 체조나 피겨스케이팅 등의 채점시 최소값,최대값을 제외한 절사평균을 사용한다.
(5) 최빈값
▶ 표본최빈값 ( sample mode )
- 자료 중 빈도가 가장 많은 값이다.
- 최빈값은 여러 개가 나올 수 있다.
- 연속자료의 경우 없을 수도 있다.
'통계학 공부' 카테고리의 다른 글
| 9. 수치자료의 형태 - 정규분포, 왜도, 첨도 (0) | 2023.04.19 |
|---|---|
| 8. 수치자료의 산포 - 분산, 표준편차, 분위수 (1) | 2023.04.18 |
| 6. 데이터 시각화의 중요성을 알려주는 사례 (1) | 2023.04.16 |
| 5. 자료의 요약 정리 (0) | 2023.04.15 |
| 4. 자료의 분류와 특성 (0) | 2023.04.14 |




댓글