※ 늦게라도 "코딩"을 배워야겠다는 사람이 있다면 혹시라도 도움이 될까해서 그 동안 알게 된 내용을 공유하려고 합니다.
지난 회차에 맵플로립(Matplotlib)을 이용하여 주가 데이터의 그래프를 그리는 방법을 2회에 걸쳐서 알아봤습니다.
2022.07.11 - [파이썬과 주식] - 6. 주가 데이터 그래프 그리기 (1) feat. Matplotlib
6. 주가 데이터 그래프 그리기 (1) feat. Matplotlib
※ 늦게라도 " 코딩"을 배워야 겠다는 사람이 있다면 혹시라도 도움이 될까해서 그동안 알게 된 내용을 공유하려고 합니다. 지난 회차에 파이썬의 판다스 라이브러리에 loc,iloc를 이용하여 데이
pmxsg.tistory.com
2022.07.16 - [파이썬과 주식] - 7. 주가 데이터 그래프 그리기(2) feat. Matplotlib
7. 주가 데이터 그래프 그리기(2) feat. Matplotlib
※ 늦게라도 "코딩"을 배워야겠다는 사람이 있다면 혹시라도 도움이 될까해서 그동안 알게 된 내용을 공유하려고 합니다. 지난 회차에 맵플로립(Matplotlib)을 이용하여 주가 데이터의 그래프를 그
pmxsg.tistory.com
이번회차에는 데이터를 분석하는 법을 알아보겠습니다. 물론 데이터를 시각화하는 것도 데이터 분석의 한 방법입니다.
데이터 분석(Data Analysis)의 정의를 찾아보면, 유용한 정보를 발굴하고 결론적인 내용을 알리며 의사결정을 지원하는 것을 목표로 데이터를 정리, 변화, 모델링하는 과정이라고 합니다.
앞서 판다스 Pandas 라이브러리를 "데이터 조작 및 분석을 위한 파이썬 프로그래밍 언어용으로 작성된 소프트웨어 라이브러리" 라고 소개한 적이 있습니다. 판다스 Pandas에는 데이터 분석을 위한 다양한 함수들이 있습니다. 이동평균을 구할 때 사용했던 rolling( ) 함수, mean( ) 함수 역시 판다스의 데이터 분석에 유용한 함수입니다.
지금까지 업데이트 된 주가 데이터를 판다스 함수로 분석해 보겠습니다.
import pandas as pd
df = pd.read_csv('삼성전자0715.csv')
df

1. set_option( ) 함수
우선, 위 데이터에서 이동평균의 소숫점 이하의 숫자들을 줄여서 데이터 표기를 간략하게 해보겠습니다.
숫자 표기 형태를 지정하는 함수로는 set_option( ) 함수를 사용하여 지정할 수 있습니다.
set_option( ) 함수로 많은 것을 미리 지정할 수 있지만, 여기서는 숫자 표기를 지정해 보겠습니다.
import pandas as pd
pd.set_option('display.float_format','{:,.0f}'.format)
df = pd.read_csv('삼성전자0715.csv')
df
pd.set_option('display.float_format','{:,.0f}'.format)
"0f" 는 실수의 형태를 정수형으로 보여주는 코드 입니다. "1f" 면 소숫점 첫째짜리까지 나타내고, "2f" 면 소숫점 둘째자리까지 나타냅니다.
같은 효과를 내는 코드는 ,
pd.options.display.float_format = '{:.0f}'.format
2. describe( ) 함수
데이터분석을 데이터의 정리, 변화, 모델링하는 과정이라 한다면, 이 describe( ) 함수는 데이터의 모양을 정리해주는 함수라고 할 수 있습니다.
df.describe()" count" : 데이터 수 / 위 데이터에는 총 261 일의 자료로 구성되어 있다는 것을 보여줍니다.
"mean" : 평균을 보여줍니다. 데이터 분석을 할 때 가장 먼저 살펴보는 자료 입니다. 데이터를 한마디로 대표할 한 단어을 찾는 다면 그것은 아마도 "평균"이 될 가능성이 높습니다.
" std " : 표준편차를 보여줍니다. 실제 데이터 값이 평균을 기준으로 할 떄 얼마나 기복이 있는지를 나타냅니다.
"min" : 최소값
"25%" : 전체 데이터중 25%에 위치한 값
"50%" : 중앙값 즉 전체 데이터중에서 중앙에 위치한 값, 평균과는 다른 의미임.
"75%" : 전체 데이터중 75%에 위치한 값
"max" : 최대값
describe( ) 한 줄로 데이터 전체 요약 정보를 얻을 수 있습니다.
데이터의 열(Column)을 기준으로만 볼 수도 있습니다.


두 개이상의 열(Column)을 보려면 대괄호를 하나 더 넣어야 합니다.
describe( )로 얻은 종가에 대한 정보를 아래와 같이 시각화 해보겠습니다.
import pandas as pd
import matplotlib
matplotlib.rcParams['font.family'] ='Malgun Gothic' # 폰트설정
matplotlib.rcParams['font.size'] = 15 # 글자크기
matplotlib.rcParams['axes.unicode_minus'] = False
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("삼성전자0715.csv")
df.dropna(axis=0, inplace=True)
sns.distplot(df['종가'], bins=100)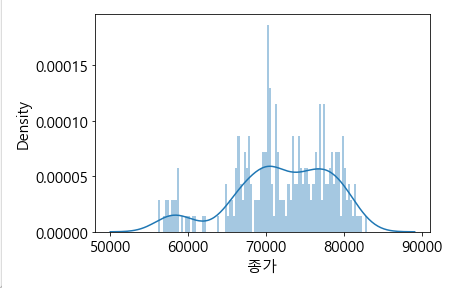
위 describe( )로 얻은 요약 정보를 이 히스토그램으로 확인해 볼 수 있습니다.
평균은 71,966 이고 50% 중앙값은 72,200 으로 평균보다 오른쪽에 위치해 있습니다.
최소값은 56,200, 최대값은 82,900 등을 그래프 안에서 확인해 볼 수 있습니다.
3. resample( ) 함수
이번에 소개할 함수는 resample( ) 입니다.
시계열( Time series)은 일정 시간 간격으로 배치된 데이터들의 수열을 말합니다.
종합 주가지수, 유가, 환율 등의 데이터들은 시계열 데이터로 볼 수 있습니다. 물론 주가 변동도 대표적인 시계열 데이터 입니다. 이러한 시계열 데이터를 분석할 때 판다스에서 기간을 설정하는 함수로는 앞서 이동평균때 사용했던 rolling( ) 함수와 함께 resample( ) 함수가 유용합니다.
이 기간 설정 함수는 기술 통계량 함수와 같이 사용합니다.
기술 통계량 함수는 mean( 평균) , median(중앙값), std(표준편차), var(분산), min(최소), max(최대), sum(합계) 등이 있습니다.
resample( ) 함수는 날짜 기간을 임의로 변경할 수 있습니다.
월 단위로는 'M' 과 "MS' 가 있습니다. M은 월말 기준으로 MS는 월초 기준으로 자료 분석을 합니다.
예를 들어 삼성전자의 월말기준 평균 주가를 구하는 코드 입니다.
import pandas as pd
pd.set_option('display.float_format','{:,.0f}'.format)
df = pd.read_csv('삼성전자0715.csv')
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
df.resample('M').mean()

두 코드는 M 과 MS로 했으나 결과값은 같습니다. 다만 M은 월말 기준으로 MS는 월초 기준으로 표기되었을 뿐입니다.
resample( ) 함수는 시계열 데이터에만 적용되기 때문에 index는 DatetimeIndex 여야 합니다.
데이터의 info( ) 를 확인해보면, RangeIndex로 나타나고, Date의 Data Type은 object 입니다.
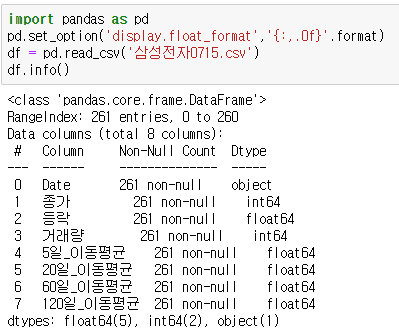
우선, Date의 Data Type을 datetime으로 바꾸어줘야 합니다.
Datetime으로 바꿔주는 함수는 to_datetime( ) 입니다.
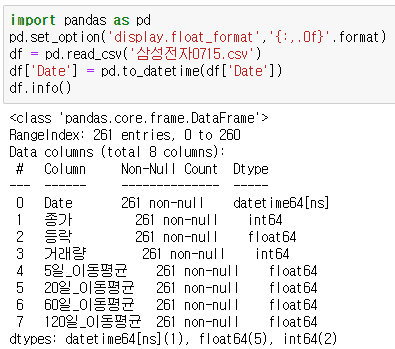
Date의 Data Type이 datetime 으로 바뀐 것을 확인할 수 있습니다.
이제 Date를 index로 설정해 보겠습니다. index로 설정하는 함수는 set_index( ) 입니다.
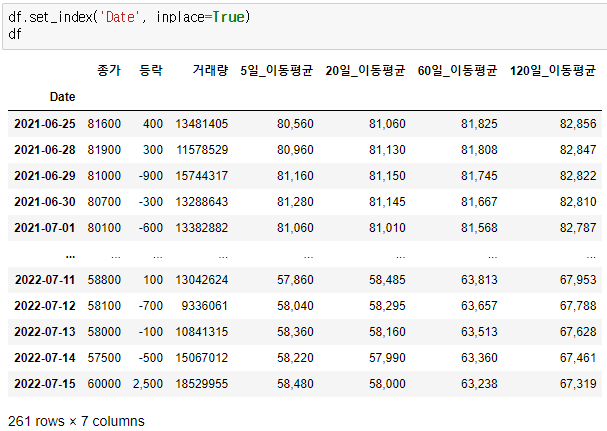
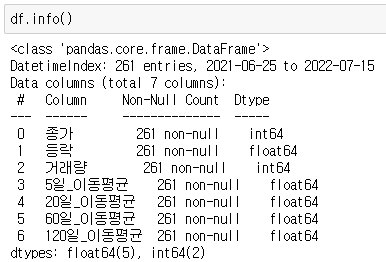
DatetimeIndex로 바뀐 것을 확인할 수 있습니다. Column에 Date가 빠진 것을 확인됩니다.
resample( ) 함수를 이용하여 월별 평균을 구해봤습니다.
종가 기준으로 막대 그래프를 그려 봅니다.
import pandas as pd
pd.set_option('display.float_format','{:,.0f}'.format)
df = pd.read_csv('삼성전자0715.csv')
df['Date'] = pd.to_datetime(df['Date'])
df.set_index('Date', inplace=True)
df_m = df.resample('M').mean()
df_m.to_csv('삼성전자m.csv')import pandas as pd
import matplotlib
matplotlib.rcParams['font.family'] ='Malgun Gothic' # 폰트설정
matplotlib.rcParams['font.size'] = 15 # 글자크기
matplotlib.rcParams['axes.unicode_minus'] = False
import matplotlib.pyplot as plt
df = pd.read_csv("삼성전자m.csv")
plt.figure(figsize=(15,5))
plt.bar(df['Date'],df['종가'])
plt.title("삼성전자 월평균 주가", color = "blue", fontsize = 25, fontweight = "bold")
plt.xticks(rotation = 45 )
plt.grid(axis='y')
plt.show()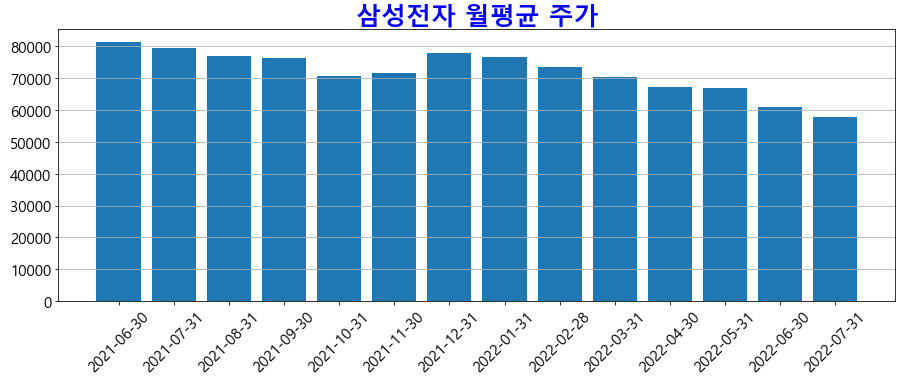
'파이썬과 주식' 카테고리의 다른 글
| 10. 파이썬 반복문을 이용한 주가 데이터 한꺼번에 다운로드 (2) (1) | 2022.09.06 |
|---|---|
| 9. 파이썬 반복문을 이용하여 여러 종목 주가 데이터 받기(1) (1) | 2022.09.01 |
| 7. 주가 데이터 그래프 그리기(2) feat. Matplotlib (0) | 2022.07.16 |
| 6. 주가 데이터 그래프 그리기 (1) feat. Matplotlib (0) | 2022.07.11 |
| 5. 주가 데이터 선택하기 feat. 판다스 Pandas ( loc, iloc ) (0) | 2022.06.22 |




댓글