※ 늦게라도 "코딩"을 배워야겠다는 사람이 있다면 혹시라도 도움이 될까해서 그동안 알게 된 내용을 공유하려고 합니다.
지난 회차에 파이썬의 판다스 라이브러리를 이용하여 기본으로 다운로드 받았던 데이터에 이동평균을 추가하는 방법을 알아 봤습니다.
2022.06.15 - [파이썬과 주식] - 4. 주가 데이터에 이동 평균 추가하기 feat. 판다스 Pandas
4. 주가 데이터에 이동 평균 추가하기 feat. 판다스 Pandas
※ 늦게라도 "코딩"을 배워봐야겠다는 사람이 있다면 혹시라도 도움이 될까 해서 그 동안 알게 된 내용을 공유하려고 합니다. 저는 50대이고 코딩시작은 2021년 11월 부터입니다. 이제 코딩이란 것
pmxsg.tistory.com
이번 회차에는 만들어진 주가 데이터에서 원하는 데이터를 선택하는 법을 알아 보겠습니다.
지난 회차에서 열(column)을 추가하고 불러 올 때는 df["열(column)이름"] 형태로 추가하거나 불러오는 것을 알아봤습니다.
이번 회차에는 행(row)을 기준으로 데이터를 선택하는 것을 알아보려 합니다.
지난 회차까지의 최신 버전 아래의 코드를 예제로 사용하겠습니다.
import FinanceDataReader as fdr
df = fdr.DataReader('005930','2021-06-03','2022-06-03')
df.rename(columns={"Close":"종가","Volume":"거래량"},inplace = True)
df.insert(5,'등락',df['종가'].diff())
df['5일_이동평균']=df['종가'].rolling(5).mean()
df['20일_이동평균']=df['종가'].rolling(20).mean()
df['60일_이동평균']=df['종가'].rolling(60).mean()
df['120일_이동평균']=df['종가'].rolling(120).mean()
df = df[['종가','등락','거래량','5일_이동평균','20일_이동평균','60일_이동평균','120일_이동평균']]
df.to_excel("삼성전자_V1.xlsx")
df.to_csv("삼성전자_V1.csv")
df
1. head ( )
행으로 선택하는 방법 중 가장 기본적인 코드 입니다.
df.head()
DataFrame에 head( )를 붙이면 데이터 처음부터 5행까지의 자료를 나타냅니다.
괄호 안에 숫자를 넣으면 숫자만큼 데이터를 나타냅니다.

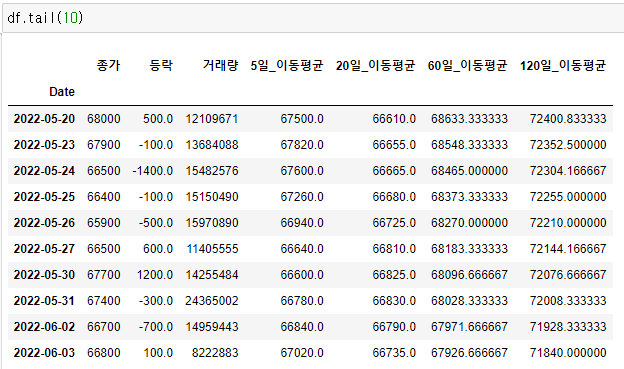
2. tail ( )
head( )의 반대 입니다. 제일 마지막 데이터 5개를 나타내 줍니다.
df.tail()
괄호 안에 숫자를 넣으면 숫자만큼 데이터를 나타냅니다.
3. loc
loc는 Pandas에서 데이터프레임 데이터를 이름을 이용해서 원하는 행(row)을 선택할 수 있는 속성입니다.
loc는 "location" 위치 라는 의미를 가지고 있습니다.
열 (column)을 선택할 때는 df["열(column)이름"] 형태로 선택할 수 있는데,
(1) 행 (row)을 선택할 때에는 df.loc["행(row) 이름"] 형태로 선택할 수 있습니다.

(2) 여러 행을 선택할 수도 있습니다.
df.loc[["2022-05-20","2022-05-30"]]
다만, 2개 이상이면 리스트가 되기 때문에 대괄호 "[ ] " 로 감싸주어야 합니다.
(3) 구간으로 선택할 수도 있습니다.
df.loc["2022-05-20":"2022-05-30"]
"행이름" : "행이름" >> 행이름을 콜론으로 연결합니다.
(2)와 (3) 에서 보듯이 대괄호 [ ] 가 1개 일때가 있고 2개 일때가 있습니다. 자료형이 리스트 형태가 되면 [ ]가 하나 더 붙습니다. 이 부분에서 에러가 많이 납니다. 에러났을 때 먼저 대괄호가 몇 개인지 확인해 보십시요.
(4) 열 (column) 중에 찾고 싶은 것 만 선택할 수 있습니다.
df.loc["2022-05-20":"2022-05-30","종가":"거래량"]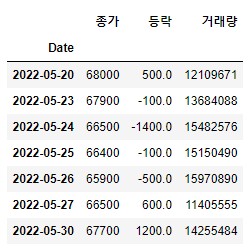
df.loc[ "행이름" , "열이름" ] >> 콤마(,)로 행이름,열이름을 열거하여 주면 됩니다.
열이름입력 방법은 행이름과 같습니다.
여러 열을 선택할 때는,
df.loc["2022-05-20":"2022-05-30",["종가","거래량","5일_이동평균"]]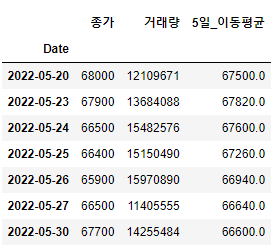
리스트 타입이므로 [ ]로 감싸주면 됩니다.
4. iloc
iloc는 Pandas에서 데이터프레임 데이터를 정수형 인덱스를 이용해서 원하는 행(row)을 선택할 수 있는 속성입니다. 즉 숫자로 위치를 선택하는 것입니다.
(1) 행 (row)을 선택할 때에는 df.iloc["행(row) 인덱스 "] 형태로 선택할 수 있습니다.
df.iloc[244]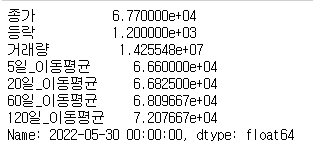
앞의 loc가 이름으로 선택하는 것이라면, iloc는 숫자로 데이터를 선택하는 것입니다. 다만, 인덱스 0 부터 시작입니다.
(2) 여러 행을 선택할 수도 있습니다.
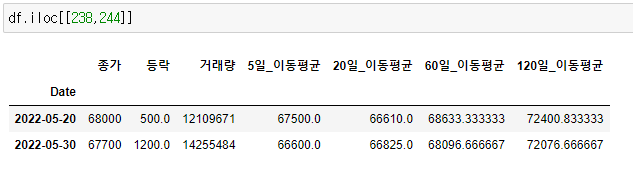
리스트 타입이므로 [ ]로 감싸주면 됩니다.
(3) 구간으로 선택할 수도 있습니다.

loc 일 때와 똑같이 콜론으로 연결해주면 됩니다. 다만 244번째까지 나타내고 싶다면 245로 표기해주어야 합니다. 0 부터 시작하기 때문에 1 차이가 납니다.
(4) 열 (column) 중에 찾고 싶은 것 만 선택할 수 있습니다.

loc와 같은 형식으로 사용할 수 있습니다. 다만, 이름대신 숫자를 쓴다는 것만 다릅니다.
5. 최신 버전
loc를 사용해서 기존 데이터를 변경해 보겠습니다.
import FinanceDataReader as fdr
df = fdr.DataReader('005930','2021-01-01','2022-06-22')
df.rename(columns={"Close":"종가","Volume":"거래량"},inplace = True)
df.insert(5,'등락',df['종가'].diff())
df['5일_이동평균']=df['종가'].rolling(5).mean()
df['20일_이동평균']=df['종가'].rolling(20).mean()
df['60일_이동평균']=df['종가'].rolling(60).mean()
df['120일_이동평균']=df['종가'].rolling(120).mean()
df = df[['종가','등락','거래량','5일_이동평균','20일_이동평균','60일_이동평균','120일_이동평균']]
df
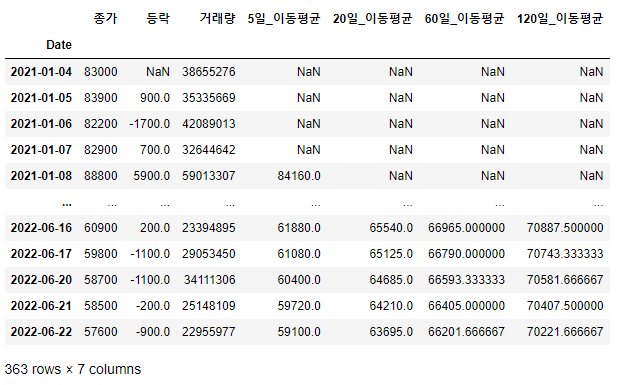
위 데이터를 보면 이동평균 데이터중 일부 "NaN"으로 표기되어 있습니다. 즉, 데이터가 비어 있다는 뜻입니다. 그래서 이동평균이 비어있는 부분은 빼고 이동평균까지 모두 차 있는 데이터만 저장하려 합니다.
df06 = df.loc["2021-06-25":"2022-06-22"]
df06.to_excel("삼성전자06.xlsx")
df06.to_csv("삼성전자06.csv")
df06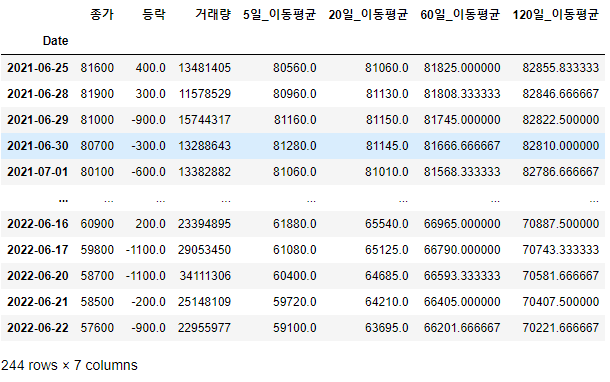
위의 작업들은 처음 다운로드를 받고 엑셀에서 작업을 할 수도 있습니다.
코딩 작업이 엑셀보다 힘들 수도 있지만, 제가 생각하는 코딩의 장점은 한 번 잘 만들어 놓은 코드는 재사용이 편리하다는 것입니다. 엑셀도 틀을 잘 잡아놓으면 많은 부분을 수정하지 않고도 사용할 수 있겠지만, 코드를 이용해 컴퓨터가 처리하는 것에 비하면 시간과 노력이 훨씬 더 많이 필요합니다.
" 잘 만들어 놓은 코드 하나 열 엑셀 부럽지 않다. "

'파이썬과 주식' 카테고리의 다른 글
| 7. 주가 데이터 그래프 그리기(2) feat. Matplotlib (0) | 2022.07.16 |
|---|---|
| 6. 주가 데이터 그래프 그리기 (1) feat. Matplotlib (0) | 2022.07.11 |
| 4. 주가 데이터에 이동 평균 추가하기 feat. 판다스 Pandas (0) | 2022.06.15 |
| 3. 파이썬 Python 개요 - 자료형(Data Type) (0) | 2022.06.09 |
| 2. 주가 데이터 다운로드 받기 ( 엑셀 / CSV ) (0) | 2022.06.03 |




댓글